|
My name is Doyoung Kim, and I am a PhD student at NYU CS, advised by Prof. Sherry Yang. Prior to this, I completed my MS at KAIST AI under Prof. Minjoon Seo. Before studying AI, I completed my BS in Mathematics & Computer Science (double major) at KAIST. I am currently interested in understanding and improving agentic capabilities of (large) neural networks in language and robotics fields, including reasoning, planning, and test-time adaptation. |

|
|
Please see my Semantic Scholar or Google Scholar profiles for the full list. * denotes equal contribution. |
|
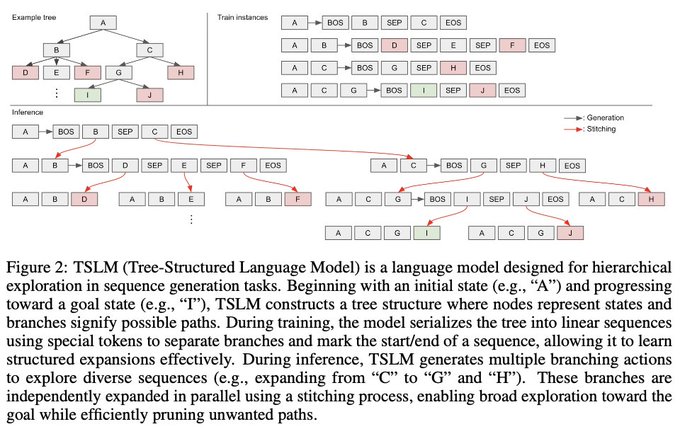
Doyoung Kim*, Jaehyeok Doo*, Minjoon Seo ICLR 2026 [paper] We propose Tree Structured Language Modeling (TSLM), a new paradigm that enables language models to generate complete search trees using special tokens rather than sequential reasoning. TSLM achieves efficient inference-time scaling by producing divergent reasoning paths in a single forward pass.
LLMs
Reasoning
|
|
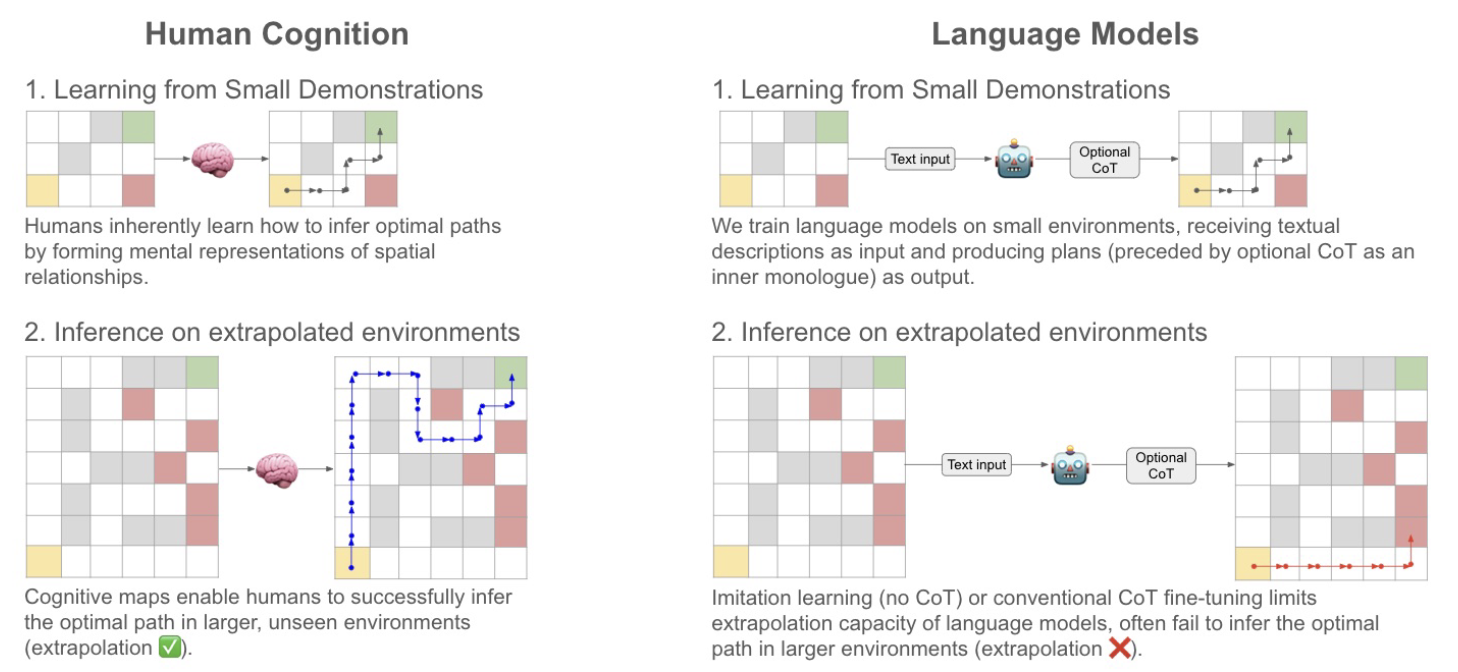
Doyoung Kim, Jongwon Lee, Jinho Park, Minjoon Seo Neurips 2024 Compositional Learning Workshop [paper] [blog] While humans can learn complex reasoning from few examples, AI struggles to generalize beyond its training. We enable language models to generate "cognitive maps" - tree-structured expansions of future states - before planning. In maze-solving tasks, this cognitive mapping approach proves to be the only effective method for helping language models extrapolate their planning abilities to larger, unseen mazes.
LLMs
Generalization
Reasoning
|
|
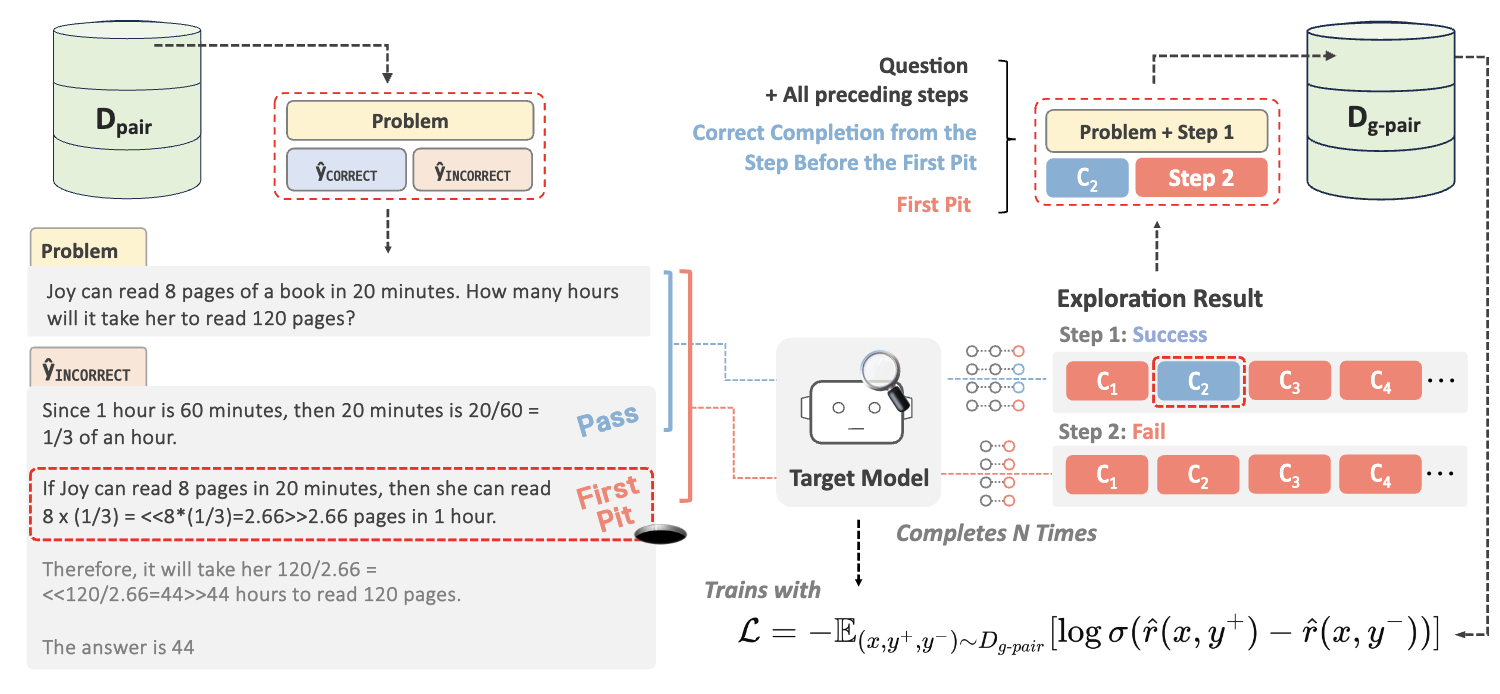
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, Minjoon Seo EMNLP 2024 Findings [paper] We propose a self-training method that helps LLMs identify their first incorrect reasoning step ("pit") and use it as a reward signal. Through preference optimization, this method enables LLMs to improve their reasoning process, leading to enhanced mathematical performance.
LLMs
Reasoning
Reinforcement Learning
|
|
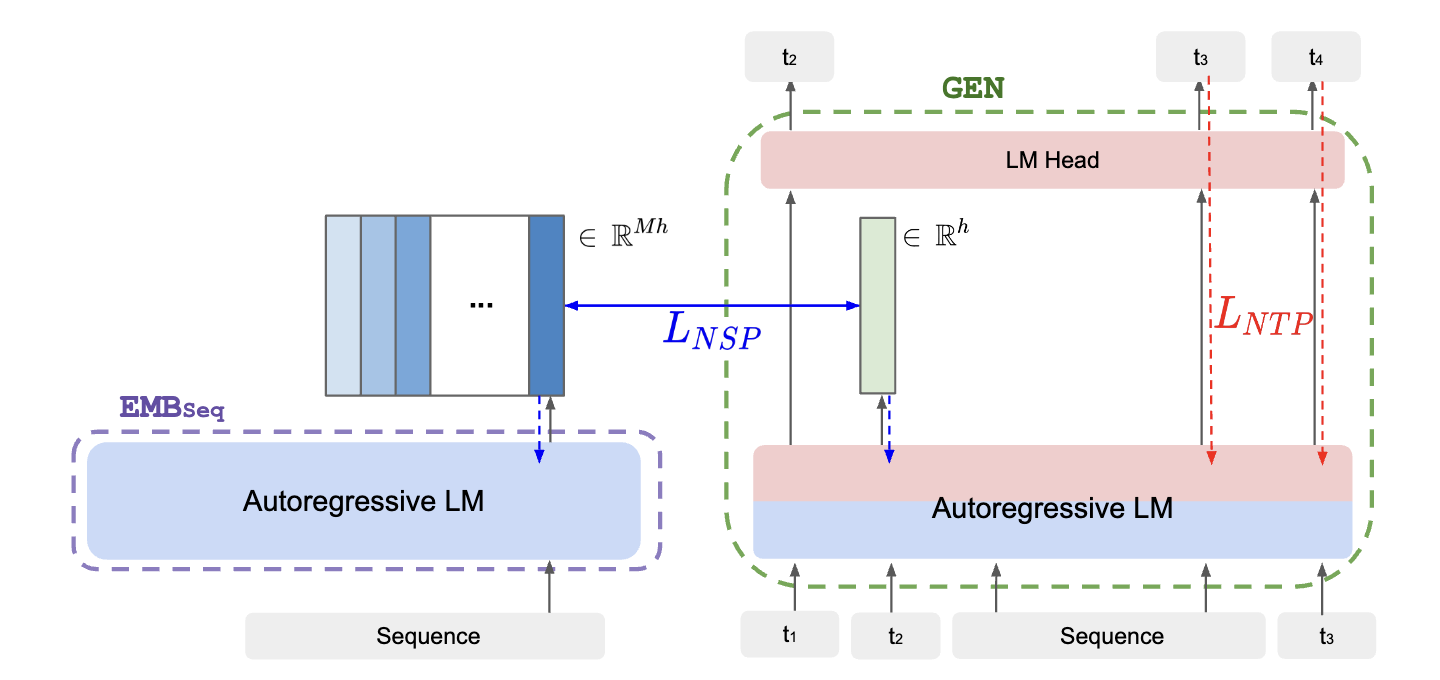
Hyunji Lee*, Doyoung Kim*, Jihoon Jun, Sejune Joo, Joel Jang, Kyoung-Woon On, Minjoon Seo ACL 2024 [paper] We introduce a semiparametric model superposing two embedding spaces: parametric token embeddings and nonparametric sequence embeddings. The model is co-trained using weighted cross-entropy loss for language modeling and InfoNCE loss for sequence retrieval to enable generation with citations.
LLMs
Retrieval
Representation Learning
|
|
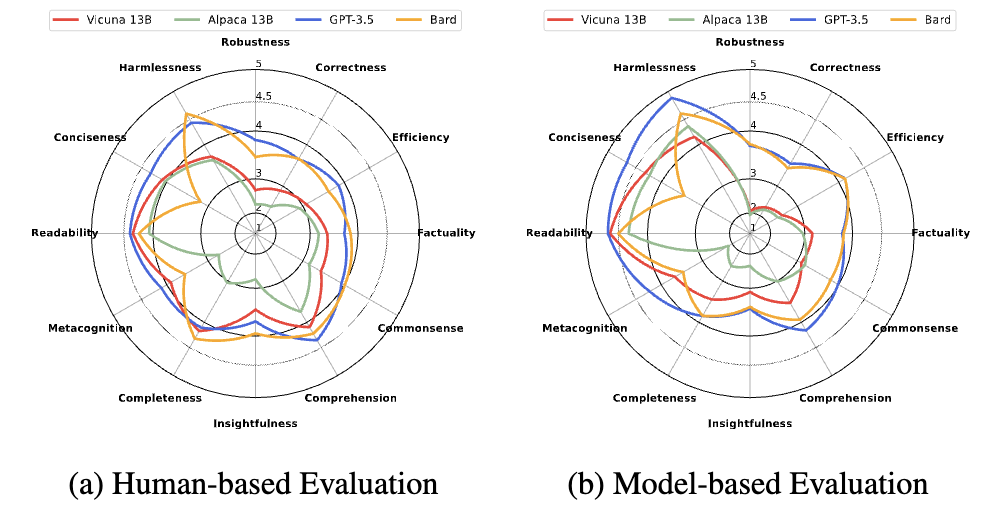
Seonghyeon Ye*, Doyoung Kim*, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, James Thorne, Juho Kim, Minjoon Seo ICLR 2024 Spotlight [paper] We propose a fine-grained evaluation framework for generative language models based on 12 alignment skill sets, which show a strong correlation between model-based and human-based evaluations.
LLMs
Evaluation
Alignment
|
|
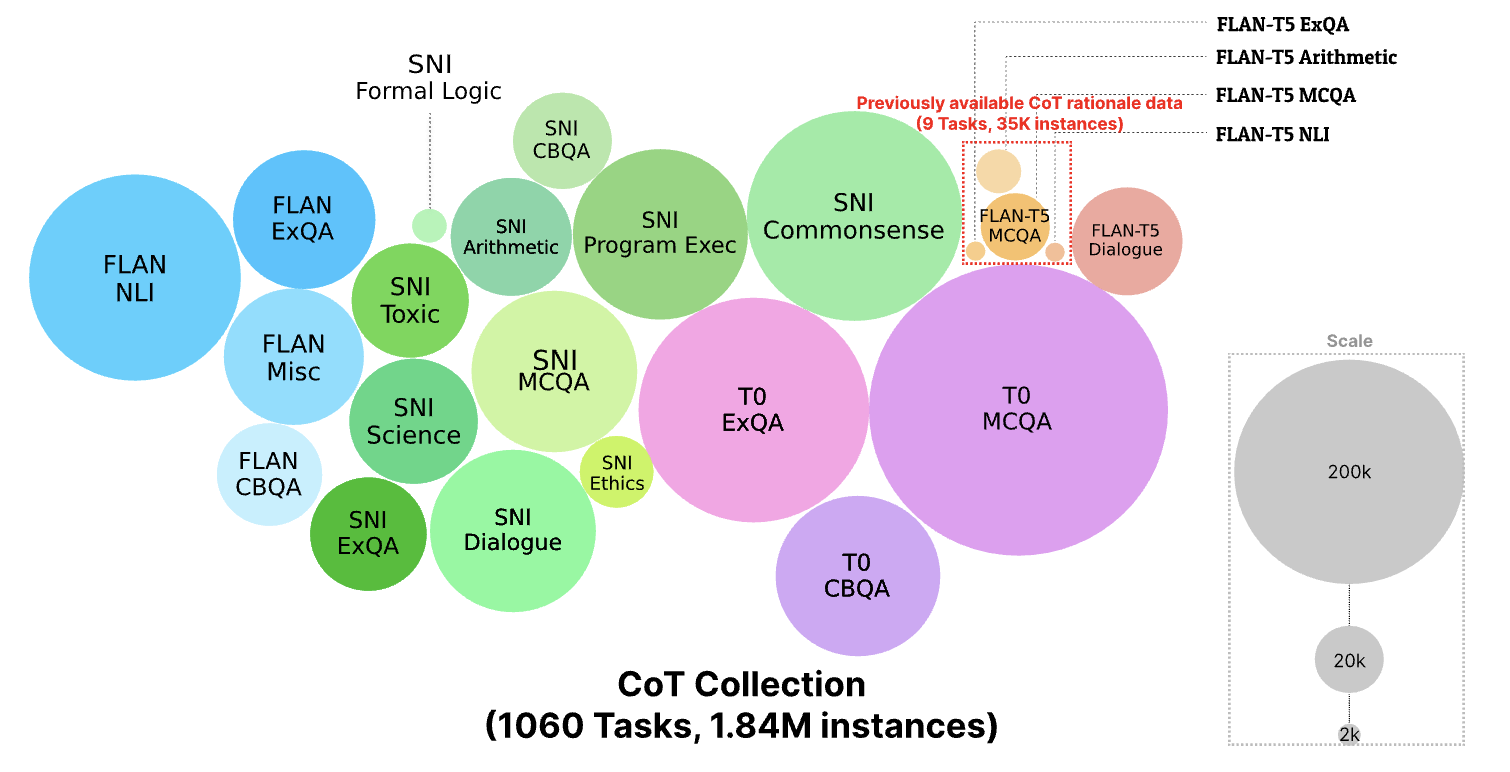
Seungone Kim, Sejune Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin, Minjoon Seo EMNLP 2023 [paper] We introduce a new instruction-tuning dataset called the COT COLLECTION dataset, containing 1.84 million rationales across 1,060 tasks. These rationales were extracted from the FLAN Collection using OpenAI Codex with in-context learning (ICL). We fine-tune Flan-T5 (3B & 11B) with the COT COLLECTION to show both zero-shot and few-shot improvements.
LLMs
Reasoning
Few-shot Learning
|
|
Show All Publications |
|
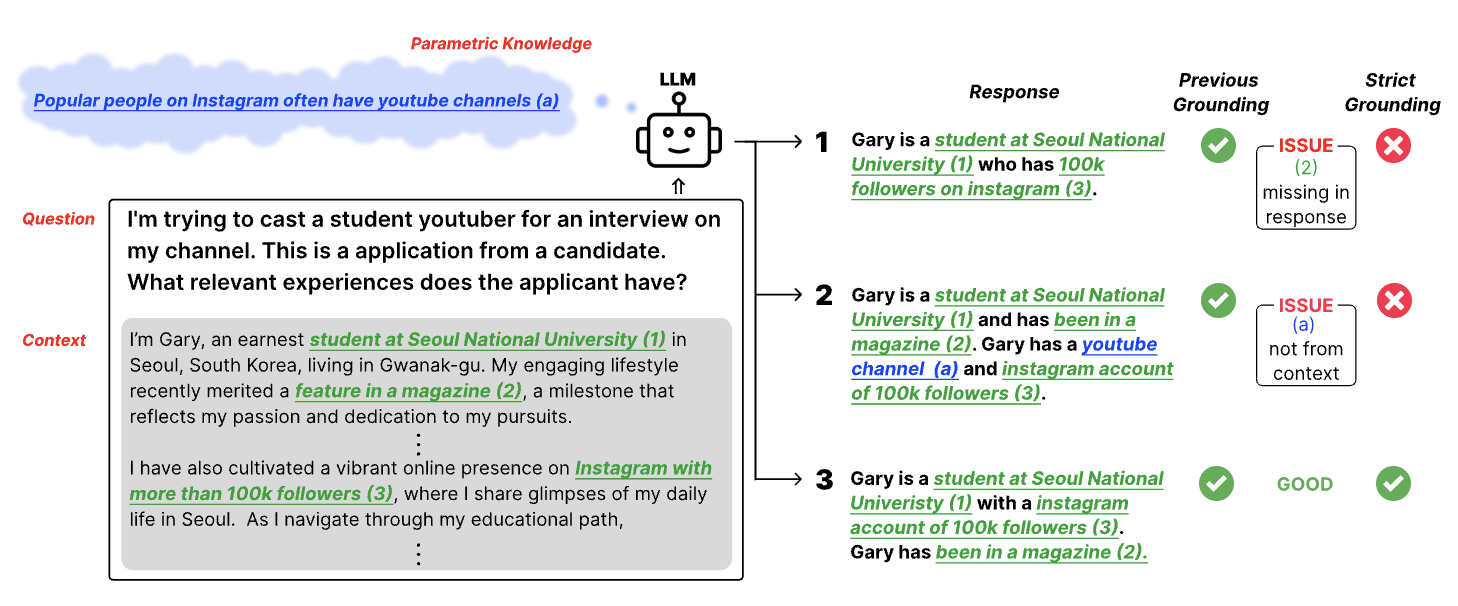
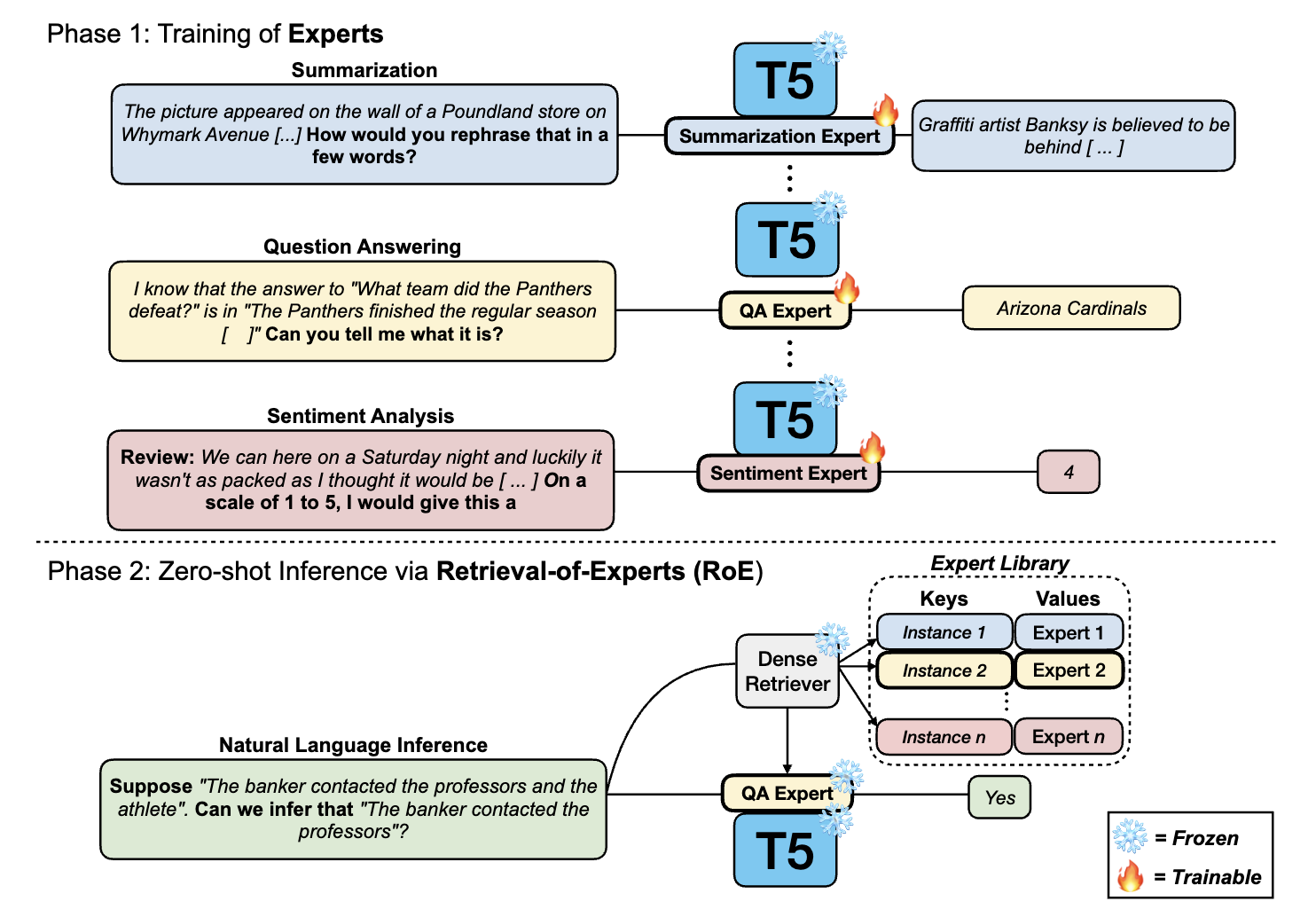
|
* denotes equal contribution. |
|
|
Seonghyeon Ye*, Yongrae Jo*, Doyoung Kim*, Sungdong Kim, Hyeonbin Hwang, Minjoon Seo [blog]
LLMs
Self-Improvement
|
|
Website design from Jon Barron |